Do you find it challenging to design a new software project?
Is it difficult to know from where to start your project?
Do you find current methodologies overcomplicated and slow?
Do you want to bring back the good old days of monolithic and waterfall model without the technical debts and legacy code?
Then this article is for you.
In my previous article, I mentioned that in Odin you can architect your software, but I didn’t go in details on how to use it in real life. For that reason, this article will introduce you to a new methodology that will give you a step-by-step guide.
This new methodology
- will be easy to learn
- will help you to devise fast
- will make your software modular
- will make your code bug-free
- will make technical debts and legacy code to disappear
- will make daily meetings disappear.
Because I am to blame for discovering this new methodology, I will call it “Can’t Driven Development” or CDD for short.
Unfortunately, this only works for programming languages that have Enum and Union types for errors, like Odin.
I promise this time I will not bash your favorite programming language.

Why we need a new methodology
We live in a different era than we did 25 years ago. For example, 25 years ago, burnout wasn’t even a thing for developers and job posts requested to know only one programming language, but today is the total opposite.
People back then had the energy and money to waste on slow paced methodologies. However, we continue to use these methodologies in today’s fast-paced and stingy market.
Even though “agile” invented to decrease the time we develop the software, but in reality it gives the illusion that is fast. It is an illusion because it gives an incomplete product to the customer with the excuse to iterate over it every week, and that iteration never ends.
And Agile moved our industry from Monolithic to Microservices and created a world where developers expected to know multiple programming languages and services. We have come to the point where companies expect only full-stack or DevOps and nothing else.
The agile movement made developers to spend multiple hours indoors and destroy their social life, just to learn all these technologies. No wonder we have a pandemic of burnouts in IT.
But the worst part is that this pandemic destroys open source. More and more open-source developers giving up because of the destruction of their social lives over the years. A good example of the results of that is XZ project.
To save this industry, we need to reduce the knowledge for developers, and I believe only Odin and CDD can do that. With this new methodology, you will be able to control every aspect of the software’s development with only one programming language.
In the next chapters, I will start explaining about CDD through a real life example.
The interview exercise
Let’s assume you signed up for an interview and the company sent you an exercise to finish in the next 8 hours.
For the exercise, the company wants a REST-API method to greet new friends, but it also wants to block annoying people.
The HTTP method is GET /hello/{name} and it will have three types of responses:
- If the person calls the REST-API method for the first time, then the REST-API will respond “Hello, nice to meet you {name}”
- If the person calls the REST-API method for the second time, but after 60 seconds, then the method will respond “Hello my friend”
- If the person calls the REST-API method repeatedly without waiting 60 seconds, then the method will respond with “Get away from me”
Also, we can’t communicate with the company to get additional information, and we have to work on this as fast as possible.
Current methodologies
Before start implementing the above exercise with CDD, let’s first explain how current methodologies can fail you.
TDD
The main idea of TDD is to design the software through tests. The developer starts coding without thinking about how to organize the code from the start, but rather from passing tests and refactoring code. This means that the developer discovers the constraints of the software through the tests and assertions, which is also the problem.
It is like putting clothes in a bag, one by one, until you figure out when it is full. Then, when it is full, you take out all the clothes from the bag to organize them before putting them back again in the bag. Nobody does that in real life and for that reason, TDD is considered slow.

DDD
Domain-Driven Design is a methodology to model source code closer to the domain of the problem. This approach developed to utilize the OOP features of the current programming languages. The purpose is to create a readable code that even non-developers could understand the intention of the code. However, that is the main issue of DDD. Developers have different views on how the domain should be represented in the code, making the code unreadable. Even DDD itself is so complicated that the author couldn’t explain it in less than 600 pages.
For our exercise, the DDD specialist will pause for hours over the board thinking existential questions like “Is the responder a class or an interface?”, “Is greeting a command or query?”, “When do I aggregate again?” … “who am I?”.

CDD
CDD is a new methodology that came to my mind accidentally when I realized that errors with Union types can model the most important aspects of the software.
It is like how Tao’s philosophy looks at objects, where it sees the design of objects through their empty spaces.
For example, the space inside a cup makes it useful for a programmer to pour coffee in.
However, in our case, the empty spaces in the software are defined by its limitation and constraints that throw errors.

To find the errors of the software you architect, then you have to ask yourself first what it “can’t” do, hence the name “Can’t Driven Development”.
The reason we start with “Can’t” and not “Can”, is because the “Can” is already defined in the customer’s request which is usually only one thing, for example in our case, adding new friends.
Our software can be explained like this, “It lets you do X, but you can’t do Y when Z, and it can’t do V”
By defining “Can’t” statements, we can really differentiate apps that do the same thing.
For example, what is the name of the app that lets you post text, but you can’t write over 280 characters? If you said X, then you are right and, thanks to that “Can’t” statement, separates it from Mastodon and Threads.
Most importantly, by defining the “can’t” statements first, we bullet-proof our software from any undefined or unexpected bugs that our users or testers would find accidentally. Everything will be defined, and you will not need to slow your software with logs.

But let me repeat that CDD to work, you have to use Odin and some rules to follow.
CDD rules
List all the “Can’t” statements
First we need to define the “Can’t” statements following these steps:
- define if a use case does exactly one thing. If it doesn’t, then it contains “Can’t” statements.
- actions that return negative results are “Can’t” statements. Negative results are the ones that contain “Not” in their explanation.
- if an action uses resources, then for these resources, you need to create “Can’t” statements to handle predefined limitations.
Translate “Can’t” statements to code
After defining the “can’t” statements, you have to write them down as error types in Odin. Before you start coding the error types, make sure you have read on how to structure errors with Odin.
Here is the list of rules that you have to follow to architect your code and start developing
- to find what functions we have to create, first we have to transform our “can’t” statements to errors and split them into functions based on a set of problems in the same domain. To achieve that, we need to refactor our error types in iterations, until the mental model is complete.
- first, take all the “can’t” statements and make them errors in an Enum for the main function.
- for the second iteration, split the errors in their own Enums based on common subject, and transform the main Enum to a Union type that contains all the newly created Enums
- repeat the above rules for all the newly created Enum types until all “can’t” statements are in their set of domains.
- define the order of errors in the types based on the order of calls in the functions.
- create the functions for the error types
- make sure they take all of their inputs from the parameters, and they don’t use any global variable.
- you can create functions that don’t return any error type to reduce the code length of your main functions
- lock the errors with switch statements in tests
- start developing your software with TDD.
- first create tests that assert stack traces and later work on the main use case.
CDD in practice
Now it is time to take all the rules and put them into practice. We will solve the exercise in the CDD way.
List “Can’t” statements
Let’s use each rule one by one for this exercise.
-
the current exercise requires for the software to return three types of responses, so it does not do one thing.
-
For our current exercise, we have two negative results. The first when the name is NOT in the friends or spammers lists, and the second is when the name is NOT friendly.
-
The resource we will use for saving lists is RAM, and it is limited. However, because everyone has different hardware, the limitations will be configurable.
So here is the list of “can’t” statements:
- If the service can’t find the name from the list of friends or spammers, then return an error and add the name to the list of friends
- The service can’t respond positively to spammers.
- If a name in the friend’s list starts to spam the service, then it can’t be in the friends list anymore.
- The service can’t accept new names when it reaches specified limits for friends or spammers.
- The service can’t accept names over a specific length.
Translate “Can’t” statements to code
Lets call our main function “hello_from” with an error type Hello_From_Error.
For starters, we create Hello_From_Error as an Enum that contains all the “Can’t” statements as errors.
Hello_From_Error :: enum {
None,
New_Spammer, // a friendly name that just moved to spammers list
Unknown, // a name that was not found in any list
Spammer, // a name that found in the spammer's list
Name_To_Long, // the name was to long
Not_Enough_Space, // there is not enough space in the lists
}
Looking at the errors, we can split them into two sets of problems. The first is about verifying the string of the name itself, and the second is about verifying the name based on the lists. They are different set of problems because they verify on different data structures.
Verify_Name_Error :: enum {
None,
Name_To_Long,
}
Verify_Friend_Error :: enum {
None,
New_Spammer,
Spammer,
Unknown,
Not_Enough_Space,
}
Hello_From_Error :: union {
Verify_Name_Error,
Verify_Friend_Error,
}
For the last iteration, we split the errors for verifying friends into two domains, the one that checks the lists and the other that adds the names to the lists. They are two different domains because they are two different actions on the same lists.
Verify_Name_Error :: enum {
None,
Name_To_Long,
}
Check_Name_Error :: enum {
None,
New_Spammer,
Spammer,
Unknown,
}
Add_Friend_Error :: enum {
None,
Not_Enough_Space,
}
Add_Spammer_Error :: enum {
None,
Not_Enough_Space,
}
Verify_Friend_Error :: union #shared_nil {
Check_Name_Error,
Add_Friend_Error,
Add_Spammer_Error,
}
Hello_From_Error :: union #shared_nil {
Verify_Name_Error,
Verify_Friend_Error,
}
Maybe you have different opinion on how the errors should be organized, but my advice is to name errors based on “can’t” statements and separate them based on data structures and actions
The most important part of this structure is the mental model it creates. We started from the error type of the main procedure, and we were able to create the rest of the procedures, like a domino effect, thanks to CDD rules.
Here you can see the diagram of the software, thanks to the errors types.
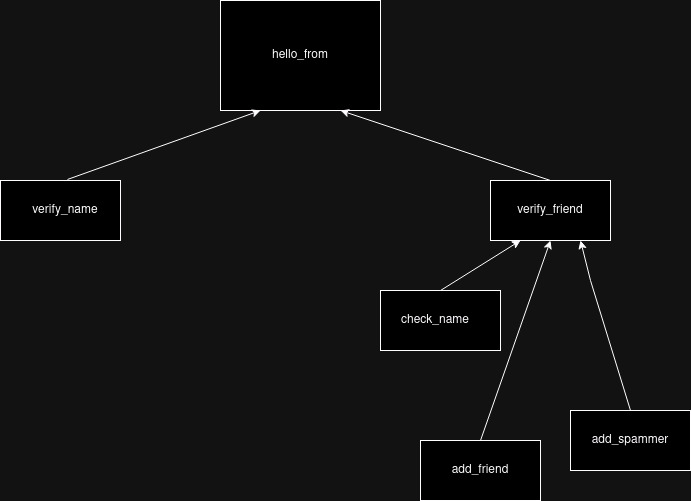
For that reason, I insist saying “the errors define your software”
Structure the code
Now it is time to structure the code for development.
First, let’s create the Struct that will contain the list of friends and spammers. I used Hashmap because it is simpler to use.
Storage :: struct {
friends: map[string]time.Time,
spammers: map[string]int,
friends_rwmutex: ^sync.RW_Mutex,
spammers_rwmutex: ^sync.RW_Mutex,
}
Secondly, we will need another one to save configurable variables like the limitations on resources.
Options :: struct {
// allowed length of a name
name_len: int,
// allowed limit of friends
friends_len: int,
// allowed limit of spammers
spammers_len: int,
// how many seconds to wait between requests
friend_until_repeat_in_sec: f64,
}
And we create each procedure for each error type using the above Structs.
hello_from :: proc(
storage: ^Storage,
opts: Options, name: string,
) -> (string, Hello_From_Error) {
return ""
}
verify_name :: proc(
opts: Options,
name: string) -> Verify_Name_Error {
return .None
}
verify_friend :: proc(
storage: ^Storage,
opts: Options,
name: string) -> Verify_Friend_Error {
return .None
}
check_name :: proc(
storage: ^Storage,
opts: Options,
name: string) -> Check_Name_Error {
return .None
}
add_friend :: proc(
storage: ^Storage,
opts: Options,
name: string) -> Add_Friend_Error {
return .None
}
add_spammer :: proc(
storage: ^Storage,
opts: Options,
name: string) -> Add_Spammer_Error {
return .None
}
However, if you want to reduce the code inside procedures, then you can create new procedures that return only values and no errors. If the newly created procedures return errors, then you have to go back to the board and iterate over “can’t” statements.
Do you see how fast we structured the software? Now we can push it to a junior developer to finish it. We can even make sure that the junior developer will not break our architecture with this test to make the compiler warn us for any breaks.
@(test)
lock_architecture :: proc(_: ^testing.T) {
_, helloErr := hello_from(storage, options, "manos")
switch err in helloErr {
case Verify_Name_Error:
switch err {
case .Name_To_Long:
case .None:
}
case Verify_Friend_Error:
switch errFriend in err {
case Check_Name_Error:
switch errFriend {
case .None:
case .New_Spammer:
case .Spammer:
case .Unknown:
}
case Add_Friend_Error:
switch errFriend {
case .None:
case .Not_Enough_Space:
}
case Add_Spammer_Error:
switch errFriend {
case .None:
case .Not_Enough_Space:
}
}
}
}
TDD on CDD
To implement the procedures, it is a good idea to use TDD. This time, TDD is faster because thanks to CDD we can test the most important parts of the software, which are the errors and stack traces.
@(test)
test_hello_from :: proc(_: ^testing.T) {
manosHello, manosErr := hello_from(storage, options, "manos")
assert(manosHello == "Hello, nice to meet you manos")
passedUnknownStackTrace := false
#partial switch friendError in manosErr {
case Verify_Friend_Error:
#partial switch checkErr in friendError {
case Check_Name_Error:
#partial switch checkErr {
case .Unknown:
passedUnknownStackTrace = true
}
}
}
assert(passedUnknownStackTrace)
}
Moreover, you will realize that we don’t need to waste time on refactoring as the structure is already prepared and by testing stack traces you do meaningful code coverage.
That is all on what I had to teach you on CDD. If you want to see the rest of the source code, then visit https://github.com/rm4n0s/hello_from
In conclusion
Parsing union trees, started as a hack in Odin, but I believe it will change how we develop software from now on because we can represent stack traces as union trees.
Like steam engines that started as a hack but soon enough changed the economy from feudalism to capitalism.
The same way, I believe that we will go from:
- Agile to Waterfall model
- Microservices to Monolithic
- DevOps to Developers
- Meetings to Forums
- Offices to Homes
- worried about system updates to pushing updates on Fridays
- legacy code, to code that does not let accidents happen from juniors.
All thanks to Odin and me for inventing CDD.

A Christmas Wish
I hope this syntactic sugar added in the #partial switch statement
#partial switch err in Union4 {
case Union3->Union2->Union1->Enum.Something:
assert(err == Enum.Something)
case Union3->Union2->Union1->Enum{Something1, Something2}:
assert(err == Enum.Something1 || err == Enum.Something2 )
}